Il 5 febbraio 2026 due rilasci quasi simultanei, Claude Opus 4.6 vs GPT-5.3 Codex, hanno riacceso la competizione tra i laboratori di IA. Dietro la narrativa “duello” c’è un punto più interessante e meno spettacolare: non stiamo assistendo solo a modelli che “scrivono meglio”, ma a sistemi sempre più agentici, progettati per sostenere attività lunghe, mantenere contesto, usare strumenti e ridurre la distanza tra ciò che chiediamo e ciò che viene effettivamente eseguito.
TL;DR tecnico
Claude Opus 4.6
- Punto forte: contesto molto ampio (citato come fino a ~1M token in alcune comunicazioni) e buona resa su knowledge work/documentazione complessa
- Profilo: più “polivalente” su compiti lunghi e multi-fonte
- Trade-off: in alcuni confronti “da coding puro” può risultare meno aggressivo rispetto a modelli ottimizzati per quel workflow
GPT-5.3 Codex
- Punto forte: orientamento chiaro ai workflow di sviluppo e prestazioni spesso riportate come solide su benchmark e task “da dev”
- Profilo: più “diretto” su iterazioni rapide (scrivi → testa → correggi)
- Trade-off: meno enfasi sul contesto estremo rispetto alla narrativa associata a Opus
Che cosa significa “IA agentica” (in parole semplici)
Per anni l’uso più comune dell’IA è stato: prompt → risposta.
L’approccio agentico sposta il baricentro verso: obiettivo → piano → esecuzione → verifica → iterazione.
Un modello “agentico” non è magia e non è autonomia totale. È, più concretamente, un sistema che tende a:
- scomporre un compito in step gestibili
- mantenere continuità su più passaggi (e non su una sola risposta)
- gestire contesto esteso (documenti, specifiche, repository, log)
- produrre output più operativi (liste d’azione, check, artefatti strutturati)
Il cambio di paradigma è qui: la differenza si vede quando il problema è reale, lungo, pieno di vincoli — non quando si tratta di scrivere tre paragrafi.
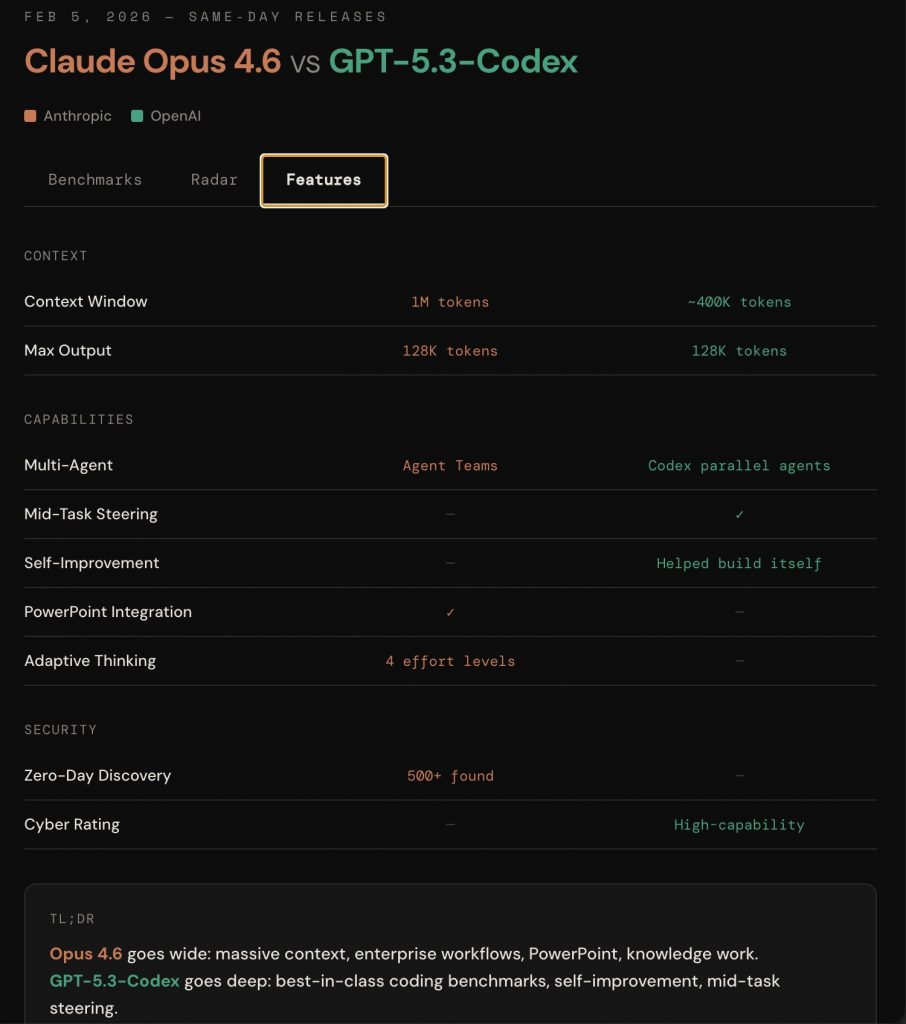
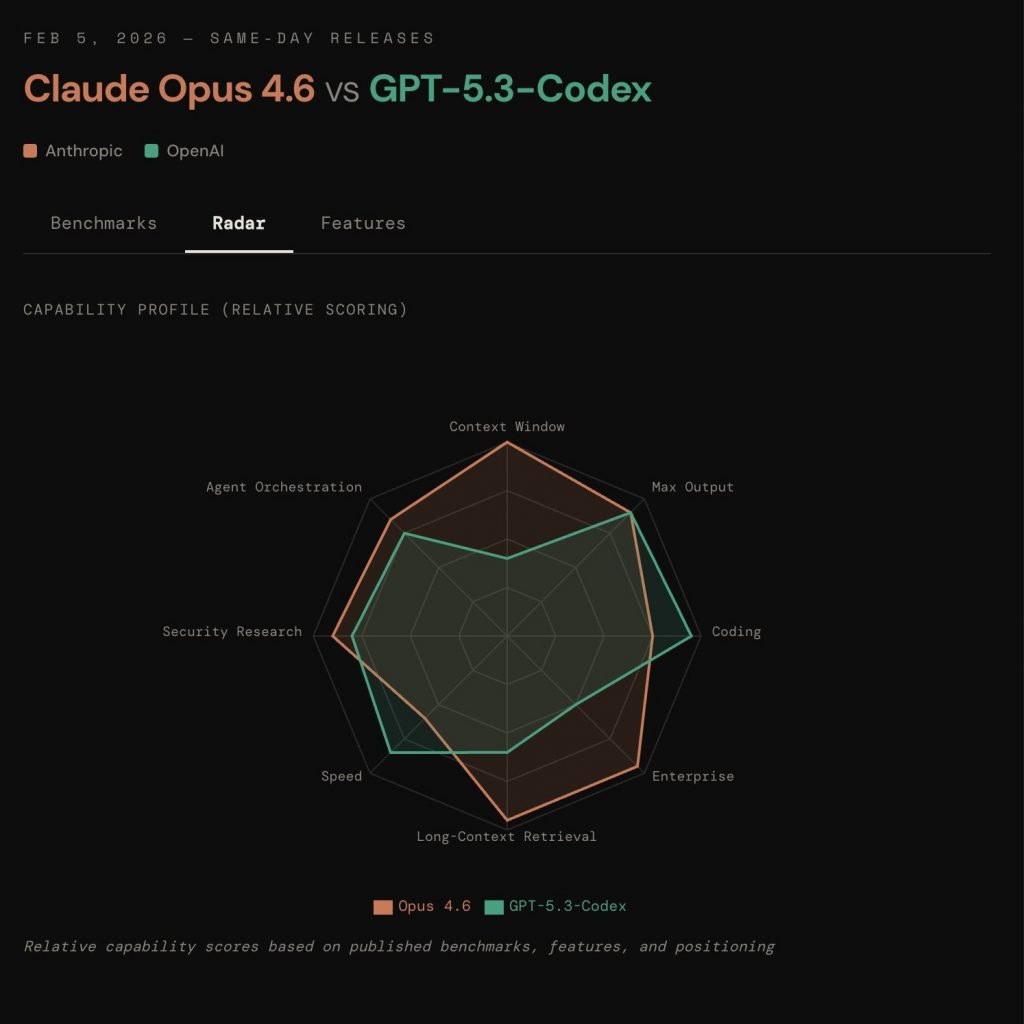
Claude Opus 4.6 vs GPT-5.3 Codex: la differenza che conta (contesto e controllo)
Una delle variabili tecniche decisive è la finestra di contesto: quante informazioni il modello può considerare insieme senza perdere coerenza.
Perché è importante?
- con contesto corto, i compiti complessi diventano “a pezzi”: riassunti aggressivi, dettagli persi, incoerenze
- con contesto lungo, diventa più realistico tenere insieme requisiti, vincoli, stile, edge case, storico decisionale e documentazione
In questa fase del mercato, però, non è solo questione di “quanto contesto”: è questione di come viene gestito (compattazione, priorità, caching, continuità di sessione).
GPT-5.3 Codex: più vicino ai workflow di sviluppo
Il nome “Codex” è un segnale chiaro: focus su coding e processi tipici dell’ingegneria software. Nelle analisi e nei confronti pubblicati sul tema, GPT-5.3 Codex viene posizionato come particolarmente orientato a task che assomigliano a lavoro reale su progetto: iterazioni rapide, correzioni, refactor, ragionamento operativo e interazione con ambienti “da dev” (anche tramite terminale/CLI).
Se guardiamo ai bisogni pratici, questo tipo di specializzazione punta a ridurre i fallimenti più comuni del coding assistito: patch isolate che non reggono su base di codice complessa, correzioni che rompono altre parti, mancanza di verifiche e continuità.
Claude Opus 4.6: contesto esteso e lavoro più “orchestrato”
Claude Opus 4.6 viene spesso descritto come modello molto competitivo in scenari in cui il contesto è enorme e interconnesso: documentazione lunga, specifiche, policy, knowledge base, codebase ampie e attività che richiedono coerenza su molti vincoli.
In particolare, il lancio è stato associato a:
- enfasi su contesto molto ampio (con indicazioni di contesto estremamente esteso in beta)
- capacità utili per task lunghi e multi-fonte
- concetti di “orchestrazione” (lavoro suddiviso e coordinato su sotto-task)
In questi scenari, il salto non è “scrive meglio”: è “resta allineato al compito mentre il lavoro cresce”.
In sintesi: Claude Opus 4.6 vs GPT-5.3 Codex è un confronto tra contesto/orchestrazione e workflow di sviluppo.
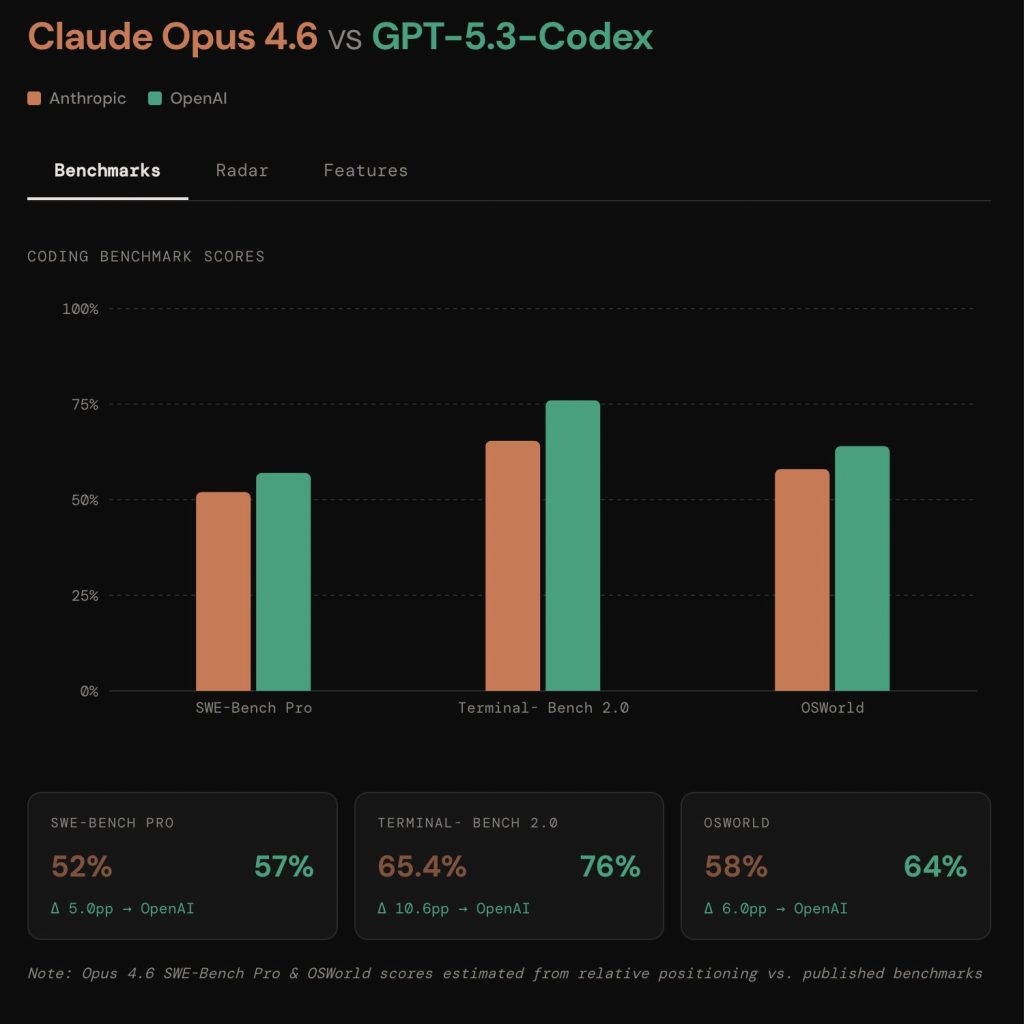
Benchmark: come leggerli senza trasformarli in una classifica assoluta
Ogni benchmark è un set di condizioni artificiali che misura una specifica abilità. È utile, ma non è il mondo reale.
Tre regole semplici:
- Benchmark diversi misurano abilità diverse (ragionamento, tool-use, coding su repo, robustezza multi-step).
- Anche lo stesso benchmark può avere varianti e protocolli: confronti “1:1” spesso sono meno lineari di quanto sembrino.
- La prova decisiva è il workflow reale: vincoli, test, revisione, ripetibilità.
I numeri aiutano a capire “dove tende a brillare” un modello, non a decretare un vincitore universale.
Il punto tecnico più importante: affidabilità, sicurezza e controllo
Quando un sistema passa dal “consigliare” al “fare”, aumenta la superficie di rischio:
- errori più costosi, perché avvengono a catena su più step
- azioni indesiderate quando entrano in gioco strumenti e automazioni
- problemi di governance (tracciabilità, versioni, dati)
- attacchi di contesto (es. prompt injection) in ambienti complessi
Qui la differenza reale non è solo potenza, ma controllabilità: definire vincoli, verificare output, limitare azioni, tracciare decisioni.
Potenza ≠ affidabilità
Un modello può essere impressionante in demo e comunque non essere pronto per compiti dove servono ripetibilità, audit e responsabilità. Nella pratica, “funziona una volta” non è una metrica.
Perché questo è un salto “di fase” (e non un aggiornamento come gli altri)
La parte più interessante di questa evoluzione è l’aumento del livello di astrazione:
- prima: automatizzazione di micro-output (testi, snippet, riassunti)
- ora: automatizzazione di blocchi di processo (pianificazione, esecuzione, verifica)
Per sfruttare davvero questi sistemi, diventano centrali tre componenti:
- Obiettivo e criteri di correttezza: cosa significa “fatto bene”?
- Struttura del contesto: cosa passa al modello, in che formato, con che priorità?
- Valutazione: test, metriche, checklist, revisione.
Se manca una di queste, l’IA non “risolve”: accelera semplicemente l’incertezza.
Cosa aspettarsi nei prossimi mesi
È ragionevole aspettarsi:
- agenti più integrati negli strumenti di lavoro (dev e office)
- miglior gestione del contesto (memoria, compattazione, caching)
- più enfasi su tool-use e governance
- maggiore attenzione a safety e controlli
Parallelamente, crescerà il rumore: demo spettacolari non sempre equivalgono a sistemi stabili e ripetibili.
Conclusione: non è “chi vince”, è che tipo di macchina stiamo costruendo
Claude Opus 4.6 e GPT-5.3 Codex mostrano la stessa traiettoria da due angoli: modelli che non si limitano a rispondere, ma che tendono a operare su compiti lunghi, vincolati e multi-step.
In questa fase, la domanda più utile non è “qual è il migliore in assoluto?”, ma:
- qual è il profilo di capacità più adatto al problema (contesto, tool-use, continuità)
- quanto è governabile il sistema (vincoli, verifica, sicurezza)
- quanto è ripetibile il risultato in un workflow reale
Il salto vero non è l’hype: è la transizione da output immediato a processo controllato.
Se dovessimo riassumere: Claude Opus 4.6 vs GPT-5.3 Codex non è una classifica, ma due profili di capacità.
FAQ
Cos’è l’IA agentica?
È un approccio in cui l’IA prova a portare avanti un compito su più step: pianifica, esegue, verifica e itera, spesso con contesto lungo e (in alcuni casi) strumenti.
Perché il contesto lungo è importante?
Perché molti lavori reali richiedono di tenere insieme requisiti, vincoli, documenti e storico delle decisioni. Più contesto (gestito bene) riduce incoerenze e omissioni.
I benchmark dicono davvero chi è “migliore”?
Danno segnali utili su abilità specifiche, ma non sostituiscono la prova nel workflow reale con vincoli, test e revisione.
Qual è il punto più importante oltre la potenza?
Affidabilità e controllo: criteri di correttezza, valutazione, governance e safety. Quando un sistema “fa cose”, l’errore costa di più e la tracciabilità diventa fondamentale.